Policy Gradients
记号:
\(\theta\) :parameters,模型参数
\(\tau\):trajectory,决策路径,形式如 \((s_1,a_1,\cdots,s_t,a_t)\)
\(r\):reward,奖励函数
\(s\) :state,状态
\(a\):action,决策行为
\(\pi\):policy,策略
-
$$
\theta^*=\arg\max_\theta E_{\tau\sim \pi_\theta(\tau)}[\sum_t r(s_t,a_t)]
$$
其实就是通过优化,找到最佳的策略参数\(\theta\) ,最大化总reward(的期望)。
直接求梯度来优化:
$$ J(\theta)=E_{\tau\sim p_\theta(\tau)}[r(\tau)]=\int \pi_\theta(\tau)r(\tau)d\tau $$$$ \begin{align} \nabla_\theta J(\theta)&=\int \nabla\pi_\theta(\tau)r(\tau)d\tau \\ &=\int \pi_\theta(\tau)\frac{\nabla \pi_\theta(\tau)}{\pi_\theta(\tau)} r(\tau)d\tau \\ &=\int \pi_\theta(\tau) \log(\nabla\pi_\theta(\tau))r(\tau)d\tau\\ &=E_{r\sim\pi_\theta(\tau)}[\log \pi_\theta(\tau) r(\tau)] \end{align} $$$$ \nabla_\theta J(\theta)\approx \frac{1}{N} \sum_{i=1}^N \left(\sum_{t=1}^T\nabla_\theta \log\pi_\theta(a_{i,t}|s_{i,t}) \right)\left( \sum_{i=1}^T r(s_{i,t},a_{i,t}) \right) $$这个公式的意义就是:sample若干条trajectories用于梯度计算(类似mini-batch),这个梯度计算是加权的,reward越大这个梯度会越大。trajectory对我们的policy进行梯度上升的结果就是policy的参数会更偏好这一条trajectory。
可以看做loss函数就是 \(-\log\pi_\theta(a|s)\) (这里我忽视了reward项),因为 \(\pi\) 实际上是一个参数化的模型(尽管其是分布,但其输出的是logits、softmax prob或分布的mean/std),那么梯度可以交由框架的autograd工具去计算;梯度下降后模型会往减少loss的方向移动,即增加\(\pi_\theta(a|s)\) 的方向,即模型会更偏向于这一条trajectory。然后实际计算时会像mini-batch一样取若干样本,取平均梯度。
一篇较为详细的BLOG:
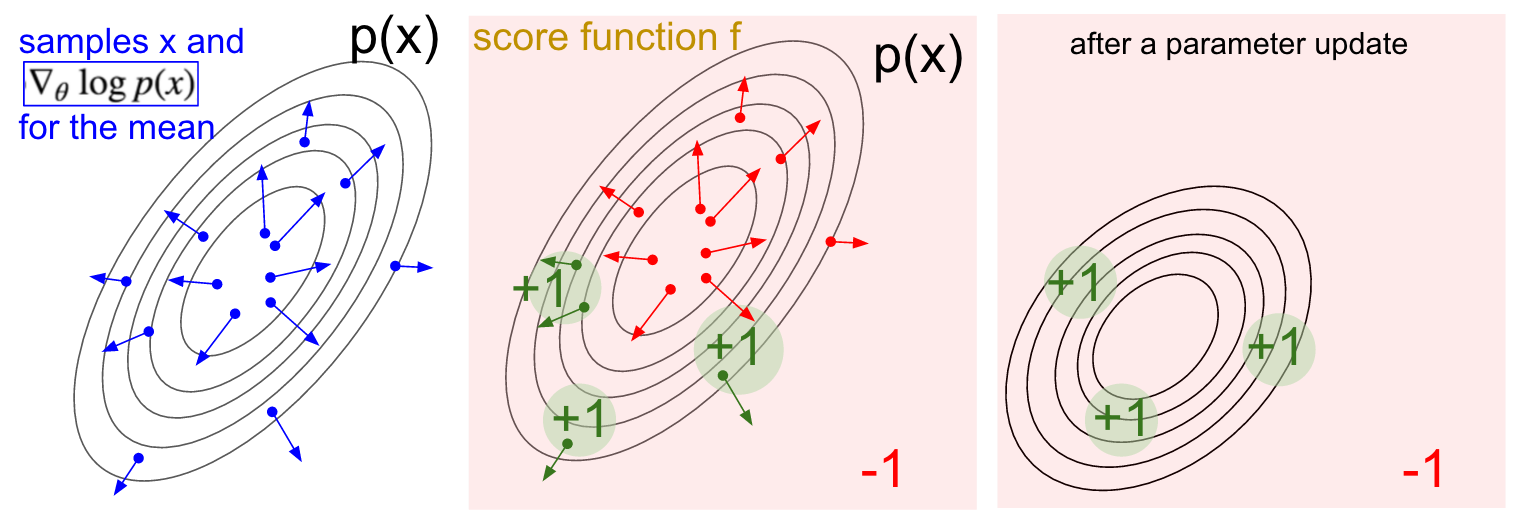
从中可以引申出基本的用policy gradient优化的算法REINFORCE:
- sample若干条trajectories \(\{\tau^i\}\)(执行我们的policy)
- 计算梯度\(\nabla_\theta J(\theta)\)
- 梯度下降更新 \(\theta\)
实际上我们会对其做很多改进:
-
reward to go
问题:sampling的方法对于模型空间(MDP转移矩阵所在的空间)和决策空间相比还是不够,会带来很大的方差。如果能减少trajectory的长度,那么就能减少方差。
reward to go方法在计算reward求和时只会从当前state \(t\) 开始计算(因为reward应当反映当前这个action的效果,而这个action和之前的reward是无关的),变相减少trajectory长度(原先对每个对数概率求梯度,都要乘上整个reward的和;现在一些项的权重会降低。但还是不太理解),从而减少variance。
-
baseline
问题:reward非零均值的情况下,比如说reward都是正数,那么所有的梯度同号,即每次梯度计算都会让模型更倾向于sample到的trajectory,这是一个正反馈过程,很容易压制其他未sample到的trajectories的出现。
baseline方法在计算reward时会减掉一个bias。实际操作中可以直接取batch中所有trajectories的reward的均值:\(b =\sum_N r(\tau)/N\) 。这其实也就是之后会提到的value function V(衡量状态好坏的价值函数)。
In pratice
pytorch官方给的distribution模块介绍中提到了Policy Gradient的过程:
probs = policy_network(state)
# Note that this is equivalent to what used to be called multinomial
m = Categorical(probs)
action = m.sample()
next_state, reward = env.step(action)
loss = -m.log_prob(action) * reward
loss.backward()
policy network输出一组概率值(类似softmax prob或logits),然后distribution模块的Categorical函数可以根据这一组概率值生成一个概率分布m,然后从中sample出当前的action。最后的loss就等于action的对数概率值乘以reward。
实际操作中更多地会先估计一个value function(如Q)来代替reward,下边的伪代码来自slide(我换成了pytorch版):
# Given:
# Actions - (N*T) * Da
# States - (N*T) * Ds
# q_values - (N*T) * 1
logits = policy.forward(states)
negative_likelihood = torch.nn.CrossEntropyLoss(logits, actions)
loss = torch.mean(negative_likelihood * q_values)
loss.backward()
然后我们来分析一下cs285 assignment工程的组成部分,以及其是如何实现policy gradient的:
utils.py 中实现了和gym.env交互的函数sample_trajectory(),它会使用当前policy和env交互,并将trajectory记录返回。它的功能是执行REINFORCE算法的第一步:sample若干trajectories。
MLP_policy.py 中的类是policy的实现,其含有一个MLP作为policy网络。主要函数有3个:
-
forward(obs):将observation传入我们的policy网络,得到网络的的输出(action的概率分布,也就是policy的输出)。 -
get_action(obs):根据observation,调用网络得到action的概率分布,从分布中sample得到一个action。 -
update(obs, actions, advantage, q_values):其作用是对网络进行更新,参数解释如下:- obs,actions:根据取样trajectory得到的obs/actions
- q_values:价值函数q,意义是当前action的期望reward,用于近似梯度中的reward求和项。
- advantage:loss中对数概率的最终权重。如果采用baseline方法,那么advantage等于q_values减去了bias(相当于reward减bias);否则其就是q_values。
这个函数会进行如下操作
- 调用policy网络得到当前policy对应当时observation的决策概率分布
- 根据当时的action求得其在分布中的对数概率,并乘以advantage值求得梯度做backward
- (如果采用baseline方法)有一个额外的网络来预测bias值(也就是value function V,此处预测的是normalize后的q_values)。函数会根据采样得到的q_values来监督训练这个网络,用MSELoss作backward。
pg_agent.py 进一步将policy和env打包抽象成agent。其主要函数有:
train(obs, actions, rewards):根据采样得到的trajectories的各项数据:- 根据rewards计算q_values(根据是否采用reward-to-go方法,加权计算的方法有所变化);
- 调用baseline网络,计算advantage值;
- 调用update进行网络的更新。
rl_trainer.py是更上级的实现,用于控制训练流程。其主要函数有:
run_training_loop():- 每次迭代都:1.使用当前policy与env交互,采样一堆trajectories保存;2.将这些trajectories用于训练。
- 注意这里有两个不同意义上的sample:一个是使用policy与env交互,sample大量trajectories;另一个是训练时从保存好的trajectories数据中sample出一个batch,用于网络的梯度计算。这种方法叫做Experience Replay,算是一种获取样本而不破坏trajectory连续性的方法。
Assignment 2: Policy Gradients
红-dsa、橙-rtg/dsa、蓝-rtg
Experiments 2
蓝、浅蓝-b100 r0.05;绿-b250 r0.01
关于张量与分布的变换可能会有用的文章:https://ericmjl.github.io/blog/2019/5/29/reasoning-about-shapes-and-probability-distributions/